Architetture software per bigdata: tutto quello che devi sapere
Scopri come le architetture per big data possono aiutare le aziende a sfruttare al meglio processandoli in modo efficiente.
"se non paghi il prodotto, il prodotto sei tu"
Questa frase di Tristan Harris, cofondatore di Center for Humane Technology, rappresenta una realtà che molti di noi spesso ignorano.
In un mondo sempre più interconnesso, ogni nostra azione online produce dati che sono raccolti e analizzati da aziende di ogni tipo. Questi dati vengono poi utilizzati per offrirci prodotti personalizzati, pubblicità mirate e, in generale, per migliorare la nostra esperienza online.
Non voglio parlarti di etica: argomento troppo complesso e fuori dall'obiettivo di questo articolo.
The most valuable commodity I know of is information.
Gordon Gekko
Voglio concentrarmi sull'importanza dei dati per una azienda - o un progetto -, ipotizzando un utilizzo etico e sempre nella direzione di creare un vantaggio per il cliente - o l'utente del sistema.
Andiamo avanti.
L'importanza dei dati va oltre la semplice personalizzazione dell'esperienza online. Le aziende utilizzano i dati anche per trarre informazioni utili sulle abitudini dei consumatori e sulle tendenze del mercato: consente loro di prendere decisioni informate e di offrire prodotti e servizi che rispondono alle esigenze dei consumatori.
Inoltre i dati sono sempre più utilizzati anche in ambiti come la ricerca scientifica, la medicina, la sicurezza nazionale e molte altre aree: la raccolta e l'analisi di grandi quantità di dati sono fondamentali per ottenere risultati significativi in queste aree.
L'utilizzo dei big data
Se guardi intorno a te, probabilmente noterai che molti dei prodotti che usi ogni giorno sono basati sui big data.
Quando navighi su Amazon, ricevi consigli per gli acquisti basati sulle tue precedenti ricerche e acquisti. Questo è possibile grazie all'analisi dei tuoi dati di navigazione, acquisto e preferenze.
Anche i social media utilizzano i dati per offrirti una migliore esperienza utente. Facebook, ad esempio, utilizza i dati delle tue interazioni sociali per offrirti contenuti personalizzati e pubblicità mirate.
Instagram, d'altra parte, utilizza i dati relativi ai tuoi interessi e alle tue interazioni con gli altri utenti per offrirti contenuti più pertinenti sulla tua home page.
Le app per la salute, come Fitbit e MyFitnessPal, utilizzano i dati raccolti dai sensori del tuo dispositivo per monitorare la tua attività fisica, il tuo battito cardiaco e la tua qualità del sonno. Questi dati vengono poi utilizzati per offrirti consigli personalizzati su come migliorare il tuo stile di vita.
Anche l'industria dell'automotive sta iniziando a sfruttare i big data. Le auto moderne sono dotate di sensori che raccolgono dati sulle prestazioni del veicolo, la posizione, il consumo di carburante e molto altro.
I dati vengono poi utilizzati dalle case automobilistiche per migliorare i loro prodotti e offrire servizi personalizzati agli utenti.
quindi i dati ci interessano solo se siamo una big tech?
No.
I big data nelle piccole aziende
Anche le aziende di piccola o media dimensione traggono enormi vantaggi dall'utilizzo dei big data.
Anzi.
Spesso sono le aziende più piccole a beneficiare maggiormente dell'analisi dei dati perché possono utilizzare queste informazioni per migliorare l'efficienza e la produttività in modo più agile rispetto alle grandi imprese.
I dati raccolti dai social media possono aiutare un'azienda a comprendere meglio i propri clienti, i loro interessi e le loro esigenze: queste informazioni possono poi essere utilizzate per sviluppare strategie di marketing più mirate e per migliorare l'esperienza dell'utente.
Inoltre, i dati possono essere utilizzati per migliorare l'efficienza delle operazioni aziendali. Ad esempio, un'azienda che produce beni di consumo può utilizzare i dati sulla domanda del mercato per migliorare la pianificazione della produzione e ridurre gli sprechi.
Infine, l'analisi dei dati può aiutare le aziende a prevenire frodi e perdite finanziarie. Ad esempio, l'analisi dei dati delle transazioni può identificare rapidamente attività sospette e segnalare potenziali frodi o errori di contabilità.
Ma cosa sono i big data?
Cosa sono i big data
Secondo la definizione di Wikipedia, i big data sono un insieme di dati di grande volume, velocità e varietà (dette anche le 3V dei big data), che richiedono strumenti avanzati e tecniche sofisticate per l'elaborazione, la gestione e l'analisi.
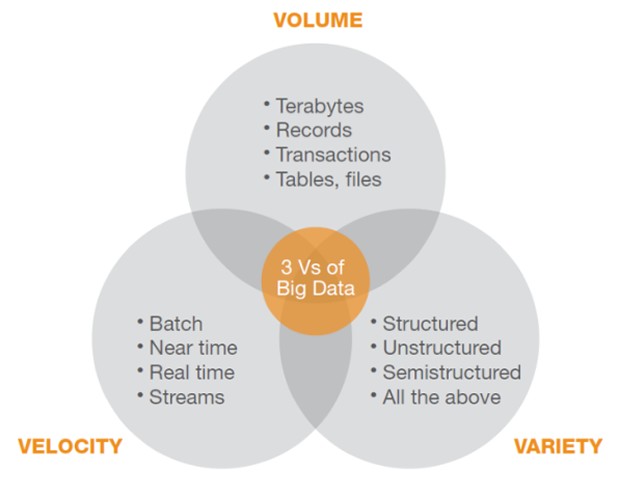
In altre parole, i big data si riferiscono ad enormi quantità di informazioni che vengono generate a un ritmo sempre più elevato da una vasta gamma di fonti, tra cui sensori, dispositivi mobili, social media, server di rete e altro ancora. Questi dati possono essere strutturati o non strutturati e possono includere immagini, video, audio e testo.
L'elaborazione dei big data richiede strumenti e tecnologie specializzati - le vedremo nel corso dell'articolo - che consentono di gestire e analizzare enormi quantità di informazioni in modo efficiente.
L'obiettivo principale dell'analisi dei big data è quello di estrarre informazioni utili e significative da questo vasto insieme di dati, utilizzando tecniche di analisi avanzate, come il machine learning e l'intelligenza artificiale.
L'analisi di questi dati può aiutare le aziende a migliorare le decisioni aziendali e identificare nuove opportunità di mercato.
Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision-making, and process automation.
Gartner
Ok, ma andiamo al sodo?
Ora parliamo di tecnologia.
La gestione dei dati in tempo reale
Con la crescita esponenziale dei dati, si è reso necessario l'utilizzo di architetture software avanzate che possano gestire grandi volumi di dati in tempo reale.
I dati possono provenire da diverse fonti, come ad esempio sensori, dispositivi mobili, social media, e-commerce, strumenti di business intelligence, e così via.
Le aziende di ogni settore possono trarre vantaggio dall'utilizzo di queste architetture di dati.
The goal is to turn data into information, and information into insight.
Carly Fiorina
Nel corso degli anni, sono state sviluppate diverse architetture software per gestire grandi volumi di dati in tempo reale.
In questo articolo parleremo di Hadoop, Lambda Architecture, Kappa Architecture e analizzeremo i pilastri tecnologici che ne costituiscono l'ossatura per processare grandi quandità di dati eterogenei in (near) real time.
Aziende come Google, Facebook, Amazon, e molte altre, utilizzano queste soluzioni architetturali per gestire grandi volumi di dati e trarre vantaggio da essi.
Ma qual'è la sfida tecnologica nella processazione dei big data?
Il CAP theorem e i sistemi distribuiti
Il CAP theorem è un concetto importante da considerare quando si sviluppano sistemi basati su big data. Secondo il teorema, in un sistema distribuito possono essere soddisfatti al massimo due dei tre requisiti seguenti: consistenza, disponibilità e tolleranza al partizionamento (Partition Tolerance).
La consistenza si riferisce alla necessità che tutti i nodi in un sistema distribuito abbiano la stessa vista dei dati in ogni momento.
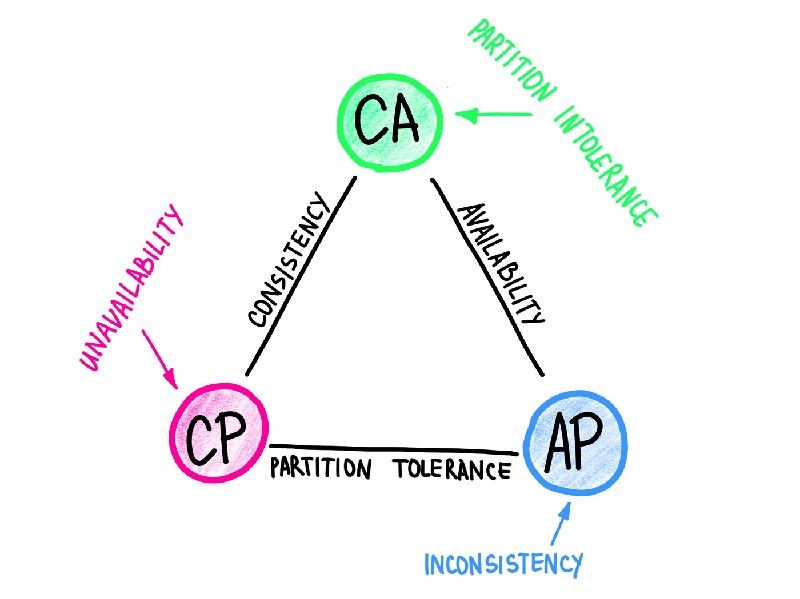
La disponibilità si riferisce alla capacità del sistema di rispondere alle richieste dei clienti in ogni momento, mentre la tolleranza al partizionamento si riferisce alla capacità del sistema di funzionare anche in caso di interruzioni di rete o di guasti hardware.
Per i sistemi basati su big data, è spesso necessario scegliere tra la consistenza e la disponibilità: le applicazioni possono essere progettate in modo da favorire la consistenza, garantendo che tutte le copie dei dati siano coerenti, oppure in modo da favorire la disponibilità, garantendo che i dati siano sempre disponibili per gli utenti, anche se non sono coerenti in ogni momento.
Ad esempio, nel caso di un sistema di elaborazione di big data in tempo reale, la priorità può essere data alla disponibilità piuttosto che alla consistenza.
In questo scenario, se una parte del sistema dovesse fallire, gli utenti sarebbero ancora in grado di accedere ai dati in tempo reale, anche se potrebbero non essere completamente aggiornati.
Il CAP theorem ha un impatto significativo sui sistemi basati su big data, poiché i progettisti devono bilanciare la consistenza e la disponibilità per garantire che il sistema funzioni in modo affidabile.
La difficoltà è trovare un compromesso tra le due proprietà, in modo da soddisfare al meglio le esigenze dell'applicazione.
Ora immagina il processo di aggiornamento del proprio profilo utente su una piattaforma di social media come Facebook.
Eventual consistency e CAP theorem
Supponiamo che un utente decida di aggiornare la propria foto del profilo.
Dopo aver caricato la nuova foto, l'utente potrebbe non vedere immediatamente la nuova foto sul proprio profilo e potrebbe vedere ancora la vecchia foto per un breve periodo di tempo.
Questo è dovuto al fatto che Facebook gestisce le foto del profilo (e gran parte dei suoi dati) con un concetto chiamato l'eventual consistency per gestire le foto del profilo.
Invece di aggiornare immediatamente tutte le copie dei dati sul sistema, Facebook permette alle copie dei dati di sincronizzarsi gradualmente, con il tempo, in modo che l'utente possa continuare a utilizzare la piattaforma senza essere interrotto dall'attesa per la sincronizzazione delle foto.
A distributed system is one in which the failure of a computer you didn't even know existed can render your own computer unusable. Leslie Lamport
Un altro esempio di questo meccanismo è il processo di acquisto online su un sito di e-commerce.
Immagina che un cliente abbia aggiunto un prodotto al carrello e stia visualizzando la pagina del carrello.
Se in quel momento l'utente aggiorna la pagina del carrello, potrebbe vedere una versione precedente del carrello con un diverso numero di prodotti.
Se noti questo effetto significa che il sistema di e-commerce utilizza l'eventual consistency per gestire i dati del carrello: le varie copie dei dati potrebbero non essere ancora sincronizzate e questo potrebbe portare a una temporanea inconsistenza dei dati visualizzati all'utente.
In entrambi questi esempi, l'eventual consistency è un compromesso accettabile per garantire che i dati siano sempre disponibili per gli utenti, anche se non sono coerenti in ogni momento.
Attenzione!
In casi in cui la consistenza dei dati è critica potrebbe essere necessario adottare soluzioni alternative per garantire che i dati siano coerenti in ogni momento.
Ma cosa significa eventual consistency?
L'eventual consistency è un concetto legato alla gestione dei dati in un sistema distribuito: in un sistema in cui ci sono più copie di un dato, non tutti i nodi del sistema vedono necessariamente la stessa versione dei dati in ogni momento.
Con l'eventual consistency si accetta che ci possano essere diverse versioni dei dati in circolazione supponendo che - alla fine - tutti i nodi vedranno la stessa versione del dato.
L'eventual consistency è spesso usata nei sistemi basati su big data, in cui la priorità è data alla disponibilità e alla scalabilità, piuttosto che alla consistenza dei dati.
In questi sistemi, i dati vengono replicati in più copie su diversi nodi del sistema per garantire la disponibilità e la tolleranza al fallimento, ma questo può comportare la comparsa di copie dei dati non coerenti.
Se la vediamo in termini di CAP theorem, l'eventual consistency è un compromesso tra la consistenza e la disponibilità: si ritiene che sia impossibile garantire sia la consistenza che la disponibilità in un sistema distribuito in cui possono verificarsi interruzioni di rete o guasti hardware.
L'eventual consistency fa ricadere la scelta sulla disponibilità a discapito della non coerenza temporanea di parte dei dati del sistema.

L'eventual consistency può essere adatta per molte applicazioni che richiedono l'elaborazione di grandi quantità di dati in tempo reale, come ad esempio la raccolta di dati per l'analisi del comportamento degli utenti in un'applicazione web o mobile.
E' importante notare che ci sono anche casi in cui la consistenza dei dati è fondamentale, come ad esempio nei sistemi bancari o nelle reti di controllo industriale. In questi casi, la priorità è la consistenza dei dati, anche a discapito della disponibilità.
Bene. Questo vuol dire che se favorisco la disponibilità alla consistenza lo devo fare tutto il sistema?
No.
E' possibile dare priorità alla consistenza in alcuni "parti" del sistema e alla disponibilità in altre. Ne parleremo meglio alla fine di questo articolo.
Prima parliamo di architettura.
Architetture big data
Le architetture per big data si basano sulla gestione di grandi quantità di dati distribuiti su diversi nodi di un sistema, spesso con l'obiettivo di garantire scalabilità, affidabilità e prestazioni elevate.
Queste architetture si concentrano su diversi aspetti critici, tra cui:
-
Il bilanciamento del carico: poiché i dati sono distribuiti su diversi nodi di un sistema, è importante garantire che il carico di lavoro sia distribuito in modo uniforme tra tutti i nodi, in modo da evitare situazioni di sovraccarico o di sottoutilizzo di alcune risorse.
-
La ridondanza: per garantire l'affidabilità dei dati, le architetture per big data prevedono spesso la replicazione dei dati su più nodi del sistema. In questo modo, in caso di guasto o malfunzionamento di un nodo, i dati rimangono sempre disponibili su altri nodi del sistema.
-
La gestione delle transazioni: quando si lavora con grandi quantità di dati, può essere difficile garantire la consistenza e l'integrità dei dati. Per questo motivo, molte architetture per big data si basano su soluzioni di gestione delle transazioni distribuite, che consentono di garantire la coerenza dei dati anche in situazioni di alta concorrenza.
-
La gestione degli eventi: le architetture per big data prevedono spesso la gestione degli eventi in tempo reale, in modo da fornire risposte immediate a eventi specifici.
-
La gestione del flusso di dati: per gestire grandi quantità di dati in tempo reale, è importante avere un'architettura in grado di gestire il flusso di dati in entrata e di elaborare i dati in modo efficiente e scalabile.
In breve, la gestione di grandi quantità di dati richiede di garantire scalabilità, affidabilità e prestazioni elevate.
Big data is not about data; it’s about creating value for the customer.
Michael Schrage
Questo è il motivo della complessità di questo genere di architetture è del perché si basano su molteplici principi e tecnologie.
Se analizziamo queste architetture dal punto di vista della gestione dei dati, possiamo riassumere quattro fasi principali:
-
Ingestion: durante questa fase i dati vengono acquisiti e inseriti nel sistema. La fase di ingestion può essere suddivisa in due sottopassi: data collection e data ingestion. Durante il data collection i dati vengono raccolti da diverse fonti e in diversi formati. Nel data ingestion i dati vengono elaborati e trasformati in un formato standardizzato, in modo da poter essere utilizzati da tutta l'architettura.
-
Storage: una volta acquisiti, i dati vengono memorizzati in un sistema di storage distribuito. La fase di storage prevede la suddivisione dei dati in blocchi, che vengono replicati in modo da garantire la ridondanza dei dati.
-
Processing: durante questa fase, i dati vengono elaborati e analizzati per estrarre informazioni utili. La fase di processing prevede l'utilizzo di tecniche di elaborazione distribuita, come ad esempio Hadoop e MapReduce.
-
Retrieval: la fase di retrieval prevede l'accesso ai dati elaborati e la loro restituzione all'utente. I dati possono essere recuperati tramite query ad hoc o tramite l'utilizzo di interfacce di programmazione delle applicazioni (API).
Ora hai una idea di alto livello.
Passiamo ad analizzare alcune delle soluzioni architetturali più comuni.
Partiamo dalle cose semplici: CRUD
L'architettura CRUD (Create, Read, Update, Delete) è un approccio comune per la progettazione di applicazioni che gestiscono dati.
È basata su un'interfaccia utente semplice, in cui l'utente può creare, leggere, aggiornare e cancellare dati. In pratica, l'architettura CRUD si basa su un database relazionale, dove le tabelle rappresentano gli oggetti e le colonne rappresentano i campi.
Il vantaggio principale dell'architettura CRUD è la semplicità: è facile da comprendere e implementare. Inoltre, questo approccio è compatibile con la maggior parte dei linguaggi di programmazione e dei database relazionali, rendendo il processo di sviluppo più semplice e veloce.
Tuttavia, l'architettura CRUD ha anche alcuni difetti. In particolare, questo approccio può essere troppo limitante per applicazioni complesse. Inoltre, l'uso di un database relazionale può essere inefficiente per applicazioni che richiedono la gestione di grandi quantità di dati o che richiedono l'accesso a dati non strutturati.
L'architettura CRUD è un approccio comune e semplice per la gestione dei dati, ma può non essere adatto per applicazioni più complesse o per la gestione di grandi quantità di dati.
Se non è adatta a grandi quantità di dati, perchè ne parliamo?
Come vedrai più avanti un sistema complesso non necessariamente richiede complessità in tutte le sue componenti.
L'abilità di chi progetta sistemi complessi è suddividerlo in sotto domini e scegliere la soluzione più adatto per ognuno di essi.
Ma non ti voglio anticipare nulla. Concentriamoci sui big data e parliamo dello strumento pioneristico di questo mondo.
Hadoop e le map reduce
Hadoop non è propriamente una architettura big data: è un ecosistema utilizzato per lo più in passato come elemento centrale di una strategia di processazione di grandi quantità di dati.
Hadoop è un framework open source utilizzato per l'elaborazione di grandi quantità di dati in modo distribuito.
Il nome "Hadoop" deriva dal nome del giocattolo di peluche del figlio di uno dei creatori del framework. Hadoop è stato sviluppato inizialmente da Doug Cutting e Mike Cafarella presso il laboratorio di ricerca di Yahoo.

Hadoop si basa sulla tecnologia MapReduce, un paradigma di programmazione distribuita che suddivide i compiti in sottoparti e li esegue in parallelo su nodi diversi all'interno del cluster. Ti ho parlato di MapReduce parlando di programmazione funzionale: se vuoi approfondire, in fondo a questo articolo trovi il riferimento.
Torniamo a Hadoop. Prima ti ho parlato di ecosistema.
Infatti, il framework offre anche un sistema di storage distribuito chiamato Hadoop Distributed File System (HDFS); capace di gestire grandi quantità di dati su più nodi.
Un'altra grande caratteristica di Hadoop è che è in grado di scalare in modo orizzontale aggiungendo o rimuovendo nodi dal cluster a seconda delle necessità. HDFS è ancora oggi una delle tecnologie più utilizzate per implementare un file system distribuito.
Ricapitolando. Hadoop è composto da diversi componenti:
- Hadoop Common: una libreria di utilità e strumenti comuni utilizzati da altri moduli Hadoop.
- HDFS: un sistema di storage distribuito utilizzato per memorizzare i dati in modo affidabile su più nodi.
- MapReduce: un paradigma di programmazione distribuita utilizzato per elaborare grandi quantità di dati in parallelo su un cluster.
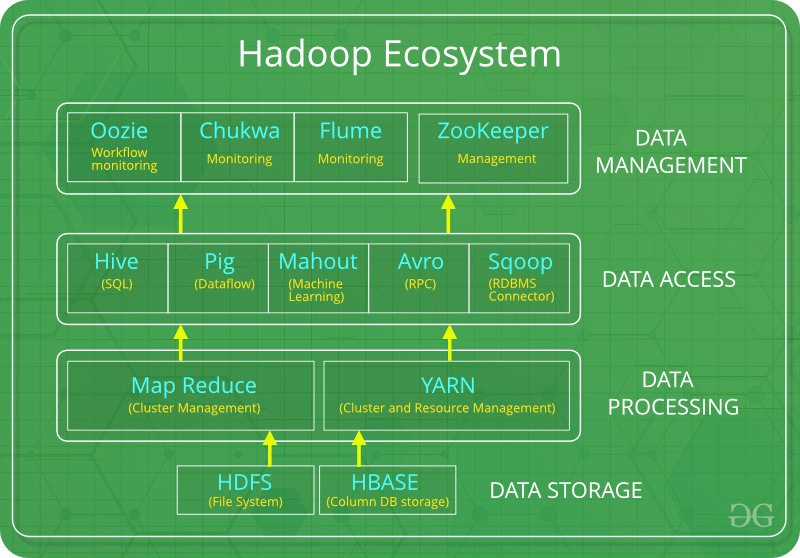
Hadoop è stato originariamente sviluppato per elaborare grandi quantità di dati strutturati, come ad esempio log file o dati di sensori: nel tempo si è evoluto per supportare anche la gestione di dati non strutturati, come ad esempio i file di testo.
I principali vantaggi e svantaggi di Hadoop
Tra i principali vantaggi di Hadoop ci sono la capacità di elaborare grandi quantità di dati in modo distribuito, la scalabilità orizzontale, la tolleranza ai guasti e la possibilità di eseguire analisi avanzate sui dati.
Hadoop ha anche alcuni svantaggi che con l'evoluzione tecnologica degli ultimi anni, non lo rendono (più) appetibile come un tempo.
La sua architettura è complessa e richiede conoscenze specialistiche per essere implementata e gestita.
Il più grosso svantaggio è il lungo tempo di elaborazione dei dati in Hadoop rispetto ad altre soluzioni più moderne: l'overhead di elaborazione causato dalla suddivisione dei dati in blocchi e l'effetto di "coda" causato dal fatto che i job vengono eseguiti in ordine cronologico ne sono il principale motivo.
Come puoi immaginare al crescere del quantitativo di dati, la lentezza di uno storage fisico (e distribuito) dove persistere i blocchi, diventa un fattore altamente penalizzante per le performance.
Hadoop per lo sviluppatore
Hadoop supporta diversi linguaggi di programmazione come Java, Python, e Scala.
Il codice di una MapReduce è costituito da due funzioni principali: la funzione map e la funzione reduce.
La funzione map prende in input una coppia chiave-valore e restituisce una lista di coppie chiave-valore intermedie.
La funzione reduce prende in input una chiave e una lista di valori intermedi e restituisce un valore aggregato.
Per testare una MapReduce, si possono utilizzare framework come MRUnit e Hadoop Unit. Questi framework forniscono un'API per testare la logica di una MapReduce senza dover effettivamente eseguire il job su un cluster Hadoop.
Di seguito un esempio di codice in Java per contare il numero di occorrenze di ciascuna parola in un insieme di documenti:
public static class WordCountMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
HDFS
Hadoop Distributed File System (HDFS) è il file system distribuito di Hadoop.
Il suo principale obiettivo è quello di consentire l'archiviazione di grandi quantità di dati in modo affidabile e scalabile.
HDFS risolve il problema di archiviare e gestire grandi volumi di dati, consentendo l'accesso a file di grandi dimensioni, che vengono suddivisi in blocchi di dimensioni predefinite e distribuiti su nodi del cluster, consentendo l'accesso parallelo ai dati.
Un altro grande vantaggio di HDFS è la sua alta tolleranza ai guasti: ogni blocco di dati viene replicato su più nodi per garantire la ridondanza dei dati e la disponibilità continua in caso di guasto di un nodo.
Esistono alcune alternative a HDFS come:
-
GlusterFS: un file system distribuito che è noto per essere molto scalabile e tollerante ai guasti.
-
Ceph: un sistema di archiviazione distribuito e altamente scalabile che può gestire dati di grandi dimensioni e altamente disponibili.
-
Lustre: un file system parallelo distribuito progettato per grandi cluster, adatto per l'elaborazione di dati scientifici e di ricerca.
-
Amazon S3: uno dei servizi di archiviazione cloud più popolari che consente di archiviare e accedere a grandi quantità di dati in modo affidabile e scalabile. Servizio analogo è fornito anche da altri cloud provider come Azure Blob o Google Cloud Storage.
Tuttavia, HDFS rimane ancora uno dei file system più popolari per la gestione di grandi quantità di dati, soprattutto perché è progettato specificamente per funzionare con Hadoop e consente una facile integrazione con altri strumenti di Hadoop come MapReduce, Hive e Pig.
Lambda Architecture
Lambda Architecture è un'architettura software utilizzata per la gestione dei big data, che si è sviluppata come soluzione alle limitazioni delle architetture tradizionali, come Hadoop.
La sua storia risale al 2011, quando Nathan Marz, un ingegnere software di Twitter, ha presentato il concetto di "Lambda Architecture" in un blog post.
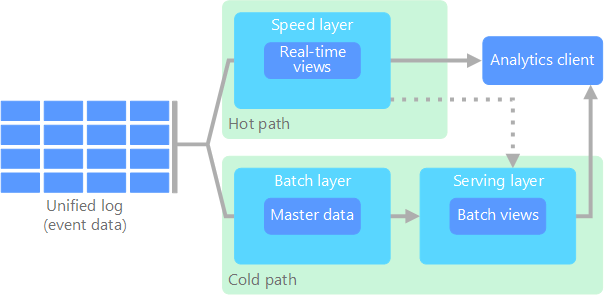
L'idea di base era quella di creare un'architettura software che potesse elaborare grandi quantità di dati in modo efficiente e scalabile, fornendo risultati in tempo reale.
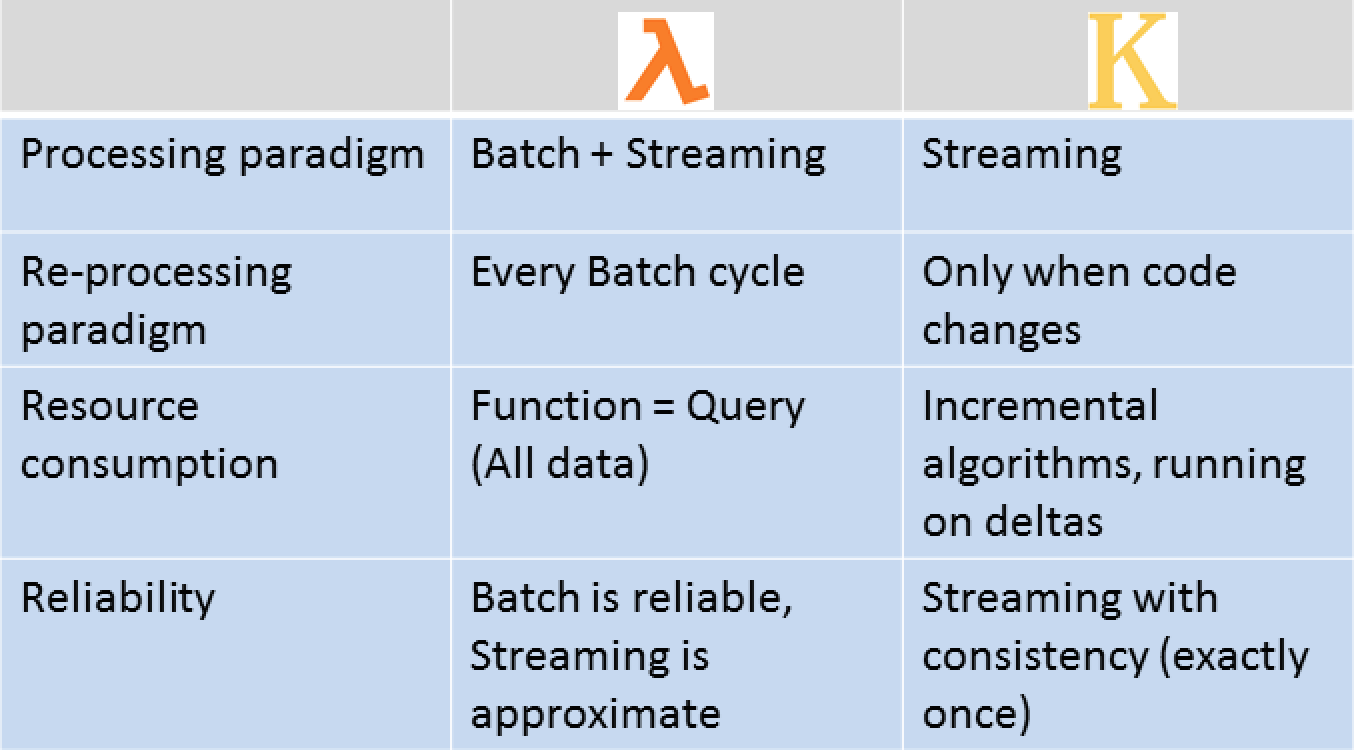
La Lambda Architecture è composta da tre componenti principali: il livello di batch processing, il livello di speed processing e il livello di storage.
Il primo livello prevede l'elaborazione di grandi quantità di dati in batch, mentre il secondo elabora in tempo reale i dati in arrivo.
Il terzo livello prevede lo storage dei dati (detto anche service layer), che si occupa di mantenere una vista aggiornata e corretta dei dati provenienti dalla elaborazione in batch e in tempo reale.
Il livello di batch processing prevede l'uso di Apache Hadoop o sistemi simili per elaborare grandi quantità di dati in batch.
Il livello di speed processing prevede l'uso di sistemi di stream processing come Apache Storm, Apache Spark Streaming o Apache Flink per elaborare i dati in tempo reale. Ti parlerò di stream processing in modo approfondito più avanti in questo articolo.
Il livello di storage prevede l'uso di un database NoSQL distribuito come Apache HBase o Cassandra.
Uno dei principali vantaggi della Lambda Architecture è la sua capacità di fornire risultati in tempo reale, garantendo al tempo stesso una forte affidabilità e scalabilità.
Inoltre, la Lambda Architecture fornisce una soluzione robusta per la gestione dei dati, permettendo di lavorare con grandi quantità di informazioni provenienti da fonti diverse.
Come al solito la velocità, la scalabilità e la robustezza hanno un costo.
Uno dei principali svantaggi della Lambda Architecture è la sua complessità, che richiede una conoscenza approfondita di vari strumenti e tecnologie per poter essere implementata correttamente. Inoltre, il costo di implementazione e gestione di una Lambda Architecture può essere elevato perchè lo stesso processo dati deve essere implementato sia nel batch layer che nello speed layer.
In sintesi, la Lambda Architecture è una soluzione flessibile e scalabile per la gestione dei big data, che combina le funzionalità di elaborazione batch e in tempo reale per fornire risultati affidabili e veloci.
The Lambda Architecture provides a framework for building scalable, fault-tolerant big data systems that can handle a wide range of use cases.
Martin Kleppmann
Per fortuna, con l'evolversi della tecnologia, gli stream processor sono diventati così veloci scalabili ed affidabili da ritenere superflua il batch layer e portando la scelta verso altre architetture.
Benchè non sia più una scelta diffusa, oggi la Lambda architecture rimane una architettura di straordinaria importanza perchè è la base per comprendere appieno tutti i componenti di una architettura distribuita.
Kappa Architecture
La Kappa Architecture è una alternativa alla Lambda Architecture, nata con lo scopo di semplificare la gestione dei dati all'interno dell'architettura, risolvendo alcune problematiche della Lambda Architecture.
In particolare, la Kappa Architecture elimina il batch layer presente nella Lambda Architecture, semplificando la gestione dei dati all'interno dell'architettura.
La Kappa Architecture è stata proposta per la prima volta nel 2014 da Jay Kreps, co-fondatore di Confluent, l'azienda che sviluppa Apache Kafka, un sistema di messaging distribuito.
L'idea di base della Kappa Architecture è di utilizzare un sistema di streaming continuo per elaborare i dati in tempo reale, senza dover utilizzare un layer batch per elaborare i dati storici.
La Kappa Architecture è composta da tre elementi principali: il data ingestion system, l'event stream processing system e il data storage system.
Il data ingestion system ha il compito di raccogliere i dati e di inviarli all'event stream processing system in tempo reale.
L'event stream processing system elabora i dati in tempo reale e li invia al data storage system per la memorizzazione a lungo termine.
Uno dei principali vantaggi della Kappa Architecture rispetto alla Lambda Architecture è la maggiore semplicità di gestione dei dati.
La Kappa Architecture permette di ridurre la latenza nella gestione dei dati, in quanto elimina il layer batch presente nella Lambda Architecture.
The Kappa Architecture is a streamlined version of the Lambda Architecture that focuses on the power of stream processing to provide fast, real-time insights into your data.
Jay Kreps
Le differenze tra Lambda e Kappa Architecture
Nella Lambda Architecture, il layer di batch viene mantenuto e processato in modo indipendente dal layer di stream, con l'obiettivo di garantire una maggiore affidabilità e consistenza dei dati. Successivamente, i dati provenienti dal layer di batch e quelli provenienti dal layer di stream vengono uniti in un unico output.
Nella Kappa Architecture, il layer di batch viene eliminato e il layer di stream diventa l'unica fonte di dati. Tutti i dati vengono elaborati in tempo reale dal layer di stream, eliminando la necessità di unire i dati di batch e stream.
La Kappa Architecture risolve il problema dell'integrazione dei dati tra il layer di batch e quello di stream, semplificando il processo di gestione dei dati e riducendo i costi.
Anatomia di una architettura big data
Abbiamo discusso le principali problematiche dei sistemi distribuiti e visto le architetture che promettono di risolverli.
Se analizziamo un sistema distribuito possiamo semplificarne la struttura in 3 principali blocchi:
- data ingestion
- sistema (distribuito) di messaggistica
- stream processing
Vediamoli nel dettagli cercando di capire perchè sono così importanti
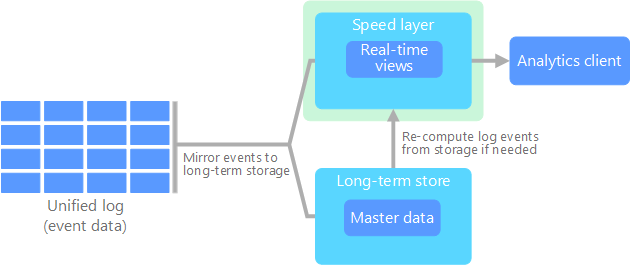
Data ingestion e Unified Log
Il data ingestion è la prima fase in cui i dati vengono acquisiti da varie fonti e archiviati in un Unified Log.
L'obiettivo principale dell'Unified Log è quello di fornire una singola fonte di dati che rappresenta tutti gli eventi nel sistema, indipendentemente dal fatto che provengano da fonti in batch o in tempo reale.
L'organizzazione temporale dei dati è importante perché permette di mantenere un'immagine coerente del sistema in ogni momento.
Il log è processato dal Batch o Speed layer per la creazione di una vista immutabile del sistema, in cui i dati sono organizzati in base al tempo e archiviati in modo permanente.
Lo Unified Log ha la caratteristica di essere l'unica, vera e immutabile fonte di verità (single point of true) del tuo sistema.
L'immutabilità dello Unified Log ha il grande vantaggio di permetterti di ricostruire lo stato del sistema in caso la vista del tuo service layer sia corrotta a causa di errori di sistema o di bug.
Non solo.
Avere un log temporale di eventi ti permette di costruire nuove funzionalità basate su una nuova struttura del service layer che potrai riempiere utilizzando i dati storici aggiornando il batch o speed layer e riprocessando i log.
In ultimo, lo Unified Log ti abilita scenari what if nel quale il sistema è stimolato con dati di scenari ipotetici e permette di capire come il sistema si comporterebbe in scenari particolari.
Lo stato corrente del sistema è facilmente ricostruibile processando il log originale.
Il concetto di Unified Log è fondamentale perché consente al Batch Layer e allo Speed Layer di interagire tra loro in modo sincronizzato. I dati che arrivano nel sistema vengono scritti nel Unified Log e poi distribuiti a entrambi i livelli di elaborazione.
Il Batch Layer elabora i dati in batch e archivia i risultati per l'analisi storica, mentre lo Speed Layer elabora i dati in tempo reale per fornire una vista aggiornata del sistema.
In questo modo, i dati che vengono processati dal Batch Layer sono gli stessi dati che vengono processati dallo Speed Layer, garantendo coerenza tra le due viste del sistema.
Se l'architettura non prevede il Batch Layer, come vedremo tra poco, lo Unified Log è collegato direttamente allo stream processing tramite un sistema di messaggistica.
Di seguito è riportato un esempio di dato che potrebbe essere presente nello Unified Log:
{
"user_id": "1234",
"event_type": "purchase",
"product_id": "5678",
"timestamp": "2022-05-22T14:30:00.000Z"
}
In questo esempio, il dato rappresenta un evento di acquisto effettuato da un utente specifico.
L'identificatore dell'utente, l'evento specifico e l'identificatore del prodotto sono presenti nel dato insieme al timestamp che rappresenta il momento in cui l'evento è stato generato.
Stream processing
Lo stream processing è un servizio che si concentra sulla gestione in tempo reale dei dati in arrivo, detti stream.
Questa tecnologia è diventata sempre più importante con l'aumento dei dati in tempo reale generati dalle applicazioni mobili, dai dispositivi IoT e dalle piattaforme di social media.
Lo stream processing prevede l'elaborazione dei dati in tempo reale mentre fluiscono attraverso il sistema, anziché attendere che questi dati siano stati completamente raccolti prima di elaborarli.
In altre parole, gli stream vengono elaborati man mano che arrivano, e non in modo batch come accade in architetture come Hadoop o Lambda.
Un esempio di stream processing è l'elaborazione dei dati di un flusso di video in tempo reale. Il video viene suddiviso in frame, che vengono inviati come stream al sistema di elaborazione. Il sistema analizza ogni frame, riconosce eventuali oggetti, persone o azioni e fornisce un'elaborazione in tempo reale del video.
Lo stream processing può essere utilizzato per un'ampia gamma di applicazioni, come la rilevazione delle frodi, il monitoraggio delle prestazioni di rete, la personalizzazione del contenuto e l'elaborazione di transazioni finanziarie in tempo reale.
Stream processing is a key technology for building intelligent, real-time systems that can respond to changing conditions in the world around us.
Ellen Friedman
Il stream processing è spesso utilizzato in combinazione con altre architetture, come ad esempio Lambda Architecture (nello Speed Layer) o Kappa Architecture, per creare un sistema di elaborazione dati scalabile e affidabile.
Distributing messaging
Il distributed messaging è una tecnologia che permette di inviare e ricevere messaggi tra diversi sistemi e applicazioni distribuite. Questa tecnologia è utilizzata principalmente per la comunicazione asincrona tra sistemi, in modo da non creare dipendenze tra i vari componenti.
Esistono diversi tipi di soluzioni di distributed messaging, tra cui le message queue e le message bus.
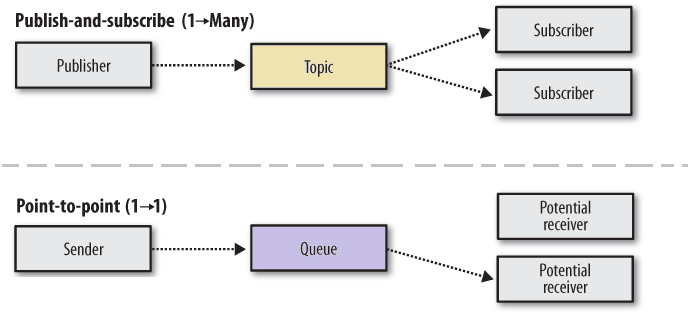
Le message queue sono caratterizzate dalla presenza di un'interfaccia in cui i messaggi vengono inseriti in modo sequenziale, e successivamente vengono letti dai vari client in modo ordinato. Questo tipo di soluzione è molto utile per garantire l'elaborazione dei messaggi in modo consistente.
I message bus, invece, sono caratterizzate dalla presenza di uno scambio di messaggi tra diversi componenti, in cui ogni messaggio viene inviato a tutti i client che sono interessati a riceverlo. In questo modo, la comunicazione tra i vari sistemi è molto più dinamica e flessibile.
Tra le tecnologie di distributed messaging più utilizzate troviamo Apache Kafka, RabbitMQ e Apache ActiveMQ.
Apache Kafka è una piattaforma di streaming distribuita in grado di elaborare flussi di dati in tempo reale, mentre RabbitMQ è una soluzione di messaging broker open source che supporta diverse tecniche di messaggistica, tra cui la pub/sub e la message queue.
Apache ActiveMQ, infine, è una piattaforma di messaging broker che supporta diverse tecnologie di messaggistica, come JMS e MQTT.
L'utilizzo di queste tecnologie di distributed messaging è sempre più diffuso in ambienti di big data, dove la comunicazione tra i vari sistemi e applicazioni è fondamentale per l'elaborazione dei dati in modo distribuito e scalabile.
Grazie alla grande velocità con cui i message bus sono in grado di processare e distribuire i messaggi, questa tecnologia è sempre più diffusa nelle architetture big data come hub di distribuzioni dei messaggi dal log all'event processor.
Event stream processing
L'Event Stream Processing (ESP) è una tecnologia che consente di elaborare in tempo reale flussi di eventi provenienti da diverse fonti di dati, come ad esempio sensori, log di applicazioni, social media e transazioni bancarie.
L'obiettivo dell'ESP è di fornire una piattaforma scalabile e performante per analizzare e processare questi flussi di eventi in modo continuo e in tempo reale.
Le tecnologie di Event Stream Processing, o ESP, si distinguono da altre tecnologie di elaborazione dei dati per la loro capacità di elaborare flussi di dati in modo continuo, anziché processare i dati in batch come avviene ad esempio con Hadoop.
Questo rende l'ESP particolarmente utile per la gestione di flussi di dati in tempo reale, come ad esempio nel monitoraggio di sensori o nella gestione di grandi volumi di dati generati da applicazioni o transazioni bancarie.
Tra le principali tecnologie di ESP possiamo citare Apache Kafka, Apache Flink, Apache Storm e Amazon Kinesis. Queste tecnologie spesso integrano funzionalità di elaborazione dei dati, come il filtraggio, l'aggregazione, il calcolo di statistiche, il machine learning e molto altro ancora.
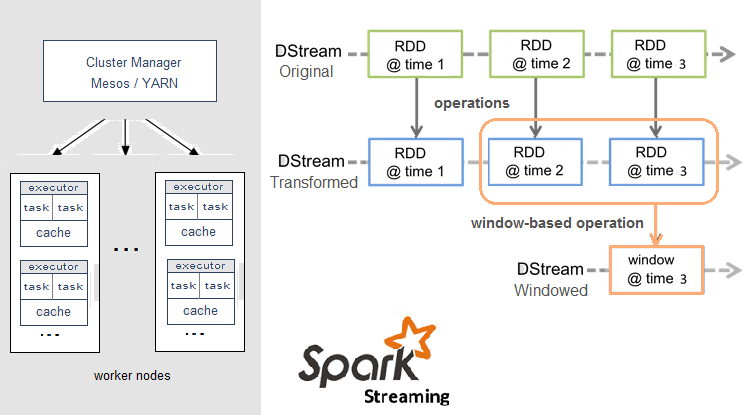
Una delle principali caratteristiche delle tecnologie di ESP è la capacità di gestire flussi di dati non strutturati e non omogenei, grazie alla presenza di metadati che descrivono il formato dei dati e il loro contenuto. In questo modo, le tecnologie di ESP consentono di effettuare analisi e elaborazioni anche su flussi di dati eterogenei e non standardizzati.
Grazie alla distribuzione del carico di lavoro su un cluster di nodi, gli ESP possono elaborare grandi volumi di dati in parallelo in modo molto rapido e a bassa latenza.
Esempio di Stream Processing
Quando si parla di sistemi di stream processing, il message bus gioca un ruolo fondamentale nella gestione dei dati. Il message bus è responsabile dell'invio dei dati dai produttori ai consumatori.
In un sistema di stream processing, l'event stream processor è il componente principale che elabora continuamente i dati provenienti dal message bus. Lo scopo dell'event stream processor è di elaborare i dati in tempo reale, consentendo di prendere decisioni e di agire rapidamente sui dati in arrivo.
Supponiamo di avere un flusso continuo di dati provenienti dai sensori di una fabbrica, che vengono inviati ad un message bus. In questo caso, il message bus funge da intermediario tra i sensori e l'event stream processor.
L'event stream processor è responsabile di elaborare i dati in tempo reale e di generare degli output, ad esempio delle statistiche sui dati raccolti.
Per implementare un sistema di stream processing con un message bus, è possibile utilizzare un framework come Apache Spark.
Ecco un esempio di codice di Spark che interagisce con Kafka che agisce da message bus:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
val topics = Set("topic1")
val kafkaParams = Map[String, String]
("metadata.broker.list" -> "localhost:9092")
val messages = KafkaUtils.createDirectStream
[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, topics)
val words = messages.flatMap(_._2.split(" "))
val wordCounts = words.map(x => (x, 1L)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
In questo esempio, viene utilizzato Kafka come message bus per ricevere i dati dai sensori. Viene poi utilizzato Spark per elaborare i dati in tempo reale e generare dei risultati. In particolare, vengono conteggiati il numero di volte che ogni parola appare nei dati raccolti.
In sintesi, il message bus e l'event stream processor sono componenti fondamentali dei sistemi di stream processing. Il message bus è responsabile della gestione dei dati in arrivo, mentre l'event stream processor si occupa di elaborare i dati in tempo reale.
Quando parliamo di stream di eventi immutabili e di denormalizzazione è naturale pensare ad Event Sourcing.
Vediamo perchè.
Event Sourcing
Event sourcing è un pattern architetturale che prevede la registrazione di tutti gli eventi che si verificano all'interno di un sistema e la loro memorizzazione in un database. Questo approccio permette di ricostruire lo stato corrente del sistema partendo da zero e riproducendo tutti gli eventi che l'hanno portato a quel punto.
In pratica, anziché memorizzare lo stato corrente del sistema, si memorizzano gli eventi che lo hanno modificato nel tempo. In questo modo, si è in grado di ricostruire lo stato corrente del sistema partendo dai dati storici.
Event Sourcing is not just about capturing events, it's about designing a system around the concepts of events and state changes.
Greg Young
Event sourcing è spesso utilizzato in combinazione con CQRS (Command Query Responsibility Segregation), un altro pattern architetturale che prevede la separazione tra la parte di scrittura dei dati (command) e quella di lettura (query).
Tra i vantaggi dell'approccio event sourcing, ci sono la possibilità di avere una visione completa del passato del sistema, la possibilità di effettuare analisi su dati storici e la possibilità di creare una traccia completa delle attività svolte all'interno del sistema.
Inoltre, event sourcing favorisce la scalabilità del sistema in quanto non vi è bisogno di memorizzare lo stato corrente del sistema in modo distribuito. Infatti, ogni nodo può lavorare sui singoli eventi senza dover memorizzare lo stato globale.
Tuttavia, event sourcing presenta anche alcuni svantaggi. In particolare, il sistema di memorizzazione degli eventi deve essere efficiente e robusto per garantire una buona prestazione e affidabilità. Inoltre, la ricostruzione dello stato corrente può richiedere tempo e risorse computazionali.
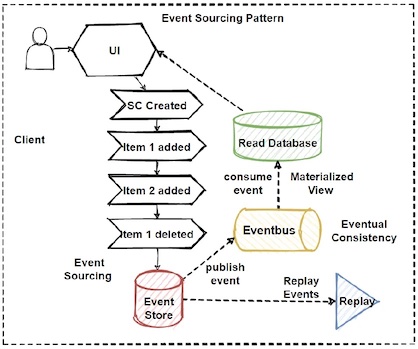
Event Sourcing vs Stream Processing
La confusione e la sovrapposizione tra i concetti di Stream Processing ed Event Sourcing possono verificarsi perché entrambi i concetti riguardano la gestione di flussi di eventi in tempo reale, ma in modo diverso.
Lo Stream Processing si concentra sulla capacità di elaborare flussi di dati in tempo reale, analizzando i dati man mano che arrivano e generando output in tempo reale. In pratica, l'obiettivo è di avere una visione in tempo reale dell'andamento dei dati.
L'Event Sourcing, d'altra parte, riguarda la registrazione di tutti gli eventi che accadono all'interno di un'applicazione, memorizzandoli in un registro immutabile. In questo modo, ogni evento che accade all'interno dell'applicazione viene salvato in modo permanente, permettendo di ricostruire lo stato corrente dell'applicazione in qualsiasi momento.
Mentre Stream Processing si concentra sulla capacità di elaborare i flussi di eventi in tempo reale, Event Sourcing fornisce una cronologia completa degli eventi che si sono verificati.
In pratica, Event Sourcing può essere utilizzato per ricostruire l'intera sequenza di eventi che hanno portato a uno specifico stato dell'applicazione, mentre Stream Processing viene utilizzato per analizzare i dati in tempo reale.
In sintesi, sebbene entrambi i concetti si occupino di eventi in tempo reale, Stream Processing si concentra sulla loro elaborazione, mentre Event Sourcing sulla loro registrazione e ricostruzione. La combinazione dei due concetti può fornire una solida base per la creazione di applicazioni reattive e scalabili, in grado di gestire grandi quantità di dati in tempo reale.
Siamo (quasi) alla fine.
Dopo questa cavalcata tra le varie e possibili scelte tecnologiche siamo al momento più importante.
Dobbiamo sviluppare un sistema complesso.
Quale architettura scegliere?
Questa è la domanda sbagliata.
Prima di dare una risposta più appropriata ho bisogno di parlarti di uno dei concetti più importanti nella progettazione di un sistema.
Un bounded context è un concetto introdotto nel Domain-Driven Design (DDD) per rappresentare un confine logico all'interno del quale i termini del linguaggio di dominio (domain language) hanno un significato preciso e condiviso tra i membri del team di sviluppo.
In pratica, un bounded context identifica un'area di comprensione specifica del business e della sua logica, dove vengono definite le regole di dominio, i processi e i flussi di lavoro. All'interno di un bounded context, un significante (parola) può assumere un significato diverso rispetto a un altro bounded context.
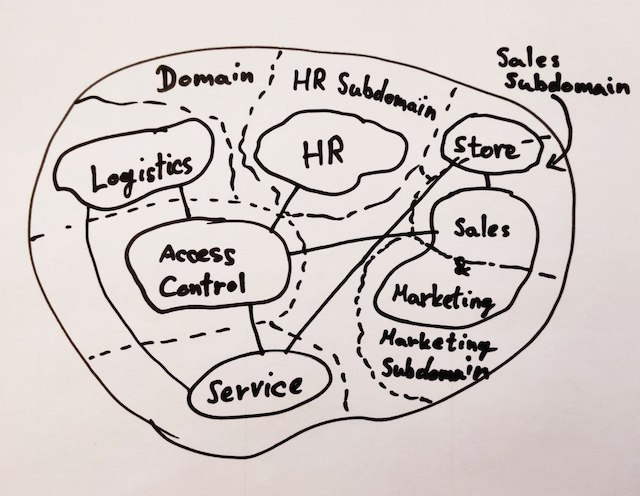
Se prendiamo un sistema di ecommerce, un prodotto (significante) ha una struttura (significante) diversa se parliamo di scheda prodotto (è composto da un nome, una immagine, un prezzo, una descrizione...) oppure del delivery del prodotto (è definito da un peso, la larghezza e lunghezza del packaging...).
La caratteristica principale dei bounded context è che sono indipendenti l'uno dall'altro: ciascuno può essere sviluppato in modo autonomo, anche utilizzando tecnologie diverse. Tuttavia, i bounded context possono interagire tra loro attraverso interfacce esplicitamente definite.
L'utilizzo dei bounded context aiuta a mantenere un'organizzazione del dominio di un'applicazione e a favorire la separazione dei concetti in modo da semplificare lo sviluppo, la manutenzione e l'evoluzione di un sistema software.
A bounded context is like a microcosm of the larger system, with its own language, rules, and context.
Eric Evans
Questo è il punto fondamentale di tutto questo articolo.
Dividere un dominio in bounded context permette di fare scelte tecniche, tecnologiche e architetturali differenti e specifiche al contesto del singolo bounded context.
Se prendiamo un ecommerce, possiamo immaginare che il BC dei pagamenti dovrà favorire la consistenza dei dati mentre in BC relativo al profilo dell'utente potrà essere sviluppato come semplice CRUD.
In ultimo, il BC relativo al product discovery (i contenuti relativi alle pagine prodotto) può essere sviluppato con una architettura event driven così da catturare gli intenti di un cliente e personalizzare l'esperienza in base ai suoi comportamenti.
Conclusione
In questo articolo abbiamo esplorato le architetture software per il trattamento di big data, concentrandoci sulla Lambda e la Kappa architecture.
Abbiamo visto come questi approcci affrontino le problematiche legate alla gestione dei dati e come utilizzino lo stream processing per ottenere risultati in tempo reale.
In particolare, abbiamo approfondito il concetto di unified log, il ruolo di message bus ed event processor e come interagiscano in un sistema di stream processing.
Abbiamo poi parlato di event sourcing, delineando come questo approccio sia utile per gestire eventi in modo efficiente.
Infine, abbiamo discusso del concetto di bounded context e del suo ruolo nell'ambito della gestione dei dati.
TI abbiamo fornito una panoramica completa delle architetture software per big data, illustrando i vantaggi e le criticità di ciascuna e fornendo un quadro generale delle tecnologie utilizzate per implementarle.
Prima di concludere ti lascio alcuni link per approfondire l'argomento di questo articolo:
-
How to beat the cap theorem - Nathan Marz: articolo in cui viene introdotta la Lambda Architecture e spiegato il suo funzionamento.
-
Big Data: Principles and best practices of scalable realtime data systems - Nathan Marz: Questo libro fornisce una panoramica approfondita sui principi fondamentali delle architetture Big Data, inclusi Hadoop, Apache Kafka e Apache Storm.
-
Turning the database inside-out with Apache Samza - Martin Kleppmann: Questo articolo offre una panoramica dettagliata su come Apache Samza può essere utilizzato per elaborare gli eventi in streaming in tempo reale.
-
Stream processing, Event sourcing, Reactive, CEP… and making sense of it all - Martin Kleppmann: L'articolo esplora come la tecnologia di stream processing può essere utilizzata con l'event sourcing e il Complex Event Processing (CEP) per creare sistemi reattivi scalabili per l'elaborazione di dati in tempo reale.
-
A Critique of the CAP Theorem - Martin Kleppman: L'articolo esamina il teorema CAP, spiegando le sue ambiguità e le inconsistenze delle definizioni, evidenziando problemi nella sua formalizzazione. Propone inoltre un nuovo framework "delay-sensitivity" come alternativa a CAP, utile per ragionare sui compromessi tra garanzie di consistenza e tolleranza di guasti di rete.
-
Kafka: The Definitive Guide" - Neha Narkhede, Gwen Shapira, e Todd Palino: Questo libro (gratuito) fornisce una guida completa per l'implementazione di Apache Kafka per l'elaborazione di dati in streaming.
-
The Reactive Manifesto - Jonas Bonér, Dave Farley, Roland Kuhn, e Martin Thompson: Questo documento descrive i principi fondamentali delle architetture reattive e le loro applicazioni in Big Data e altre applicazioni distribuite.
-
CQRS Documents - Martin Fowler: Questo documento descrive il modello di progettazione CQRS (Command Query Responsibility Segregation) e la sua applicazione nell'elaborazione di dati in tempo reale.
-
CQRS Documents - Greg Young: Questo documento descrive CQRS dal suo autore.
-
Building Data-Intensive Applications - Martin Kleppmann: Questo libro fornisce una guida pratica per la progettazione e l'implementazione di applicazioni Big Data scalabili e resilienti.
-
Learning Spark: Lightning-Fast Big Data Analysis - Holden Karau, Andy Konwinski, Patrick Wendell, e Matei Zaharia: libro che fornisce una guida completa all'utilizzo di Apache Spark per l'analisi di Big Data.
Ho scritto alcuni articoli che approfondiscono questi temi. Eccone alcuni che potrebbero interessarti.
Sarei contento se lasciassi un commento per raccontare la tua esperienza, i tuoi spunti, le tue riflessioni su questo tema o i dubbi costruttivi su questo articolo.
Parliamone ed arricchiamoci insieme.
E se vuoi, condividi questo articolo con chi pensi possa essergli utile.
Se invece sei timido o vuoi contattarmi, scrivimi
Tieni botta,
Gianluca